MNIST Examples
Both the BCM and Hopfield model are tested and compared on MNIST, the standard training dataset composed by \(70000\) images (\(28 \times 28\) pixels) of hand-written digits. In the following examples, the code for running the simulations is shown and the learned synaptic weights are depicted using an animated colormap. In this way, we can nicely visualize how these receptive fields are evolving during the training.
The simulations are executed on a network with the same structure (outputs = \(100\)), starting from the same synaptic weights initial distribution (standard normal), and fixing the number of epochs (num_epochs = \(10\)) as well as the mini-batches size (batch_size = \(1000\)).
BCM model
The first step is to import the MNIST dataset and rescale the full set of features into \([0, 1]\) to improve the model performances.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(name='mnist_784', version=1, data_id=None, return_X_y=True)
X *= 1. / 255
Then, the BCM model has to be instantiated setting its custom parameters: the most common activation functions, optimizers and weights initializers are provided in the biolearn submodules. The performances depend on the configuration of the parameters, therefore a fine tuning can lead to better results.
from biolearn.model.bcm import BCM
from biolearn.utils.activations import Relu
from biolearn.utils.optimizer import Adam
from biolearn.utils.weights import Normal
model = BCM(outputs=100, num_epochs=10, batch_size=1000,
activation=Relu(), optimizer=Adam(), weights_init=Normal(mu=0., std=1.),
interaction_strength=0.)
In this case, a Relu activation and an Adam optimizer are used and the BCM model has no lateral interactions at all. The last step is to call the fit method to run the training.
model.fit(X)
The final result can be visualized using the view_weights function in the utils submodule.
from biolearn.utils.misc import view_weights
view_weights(model.weights, dims=(28,28))
To further improve the results visualiation, here it is shown the colormap evolving over time during training.
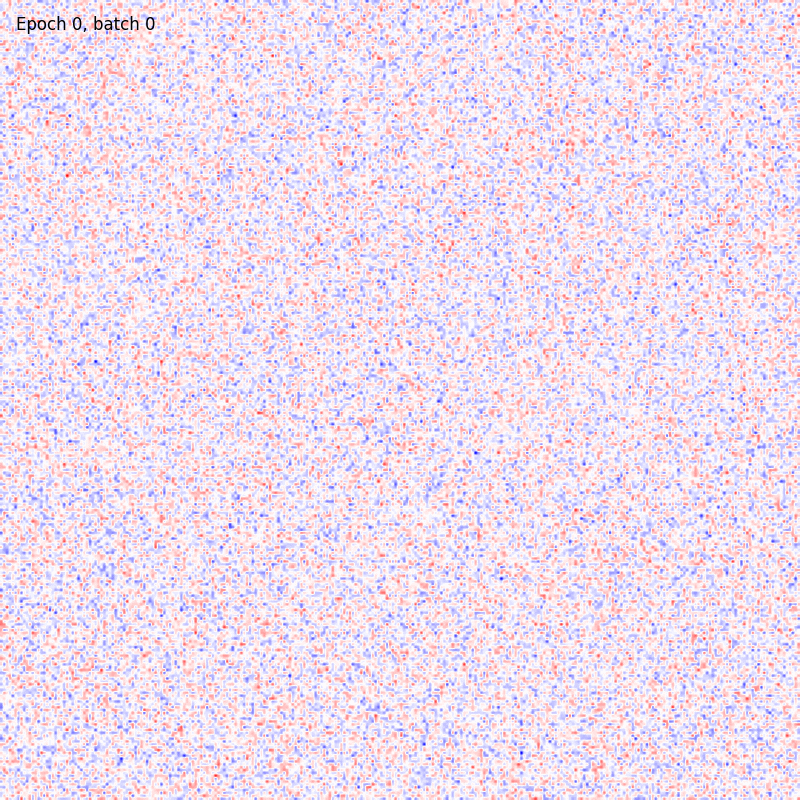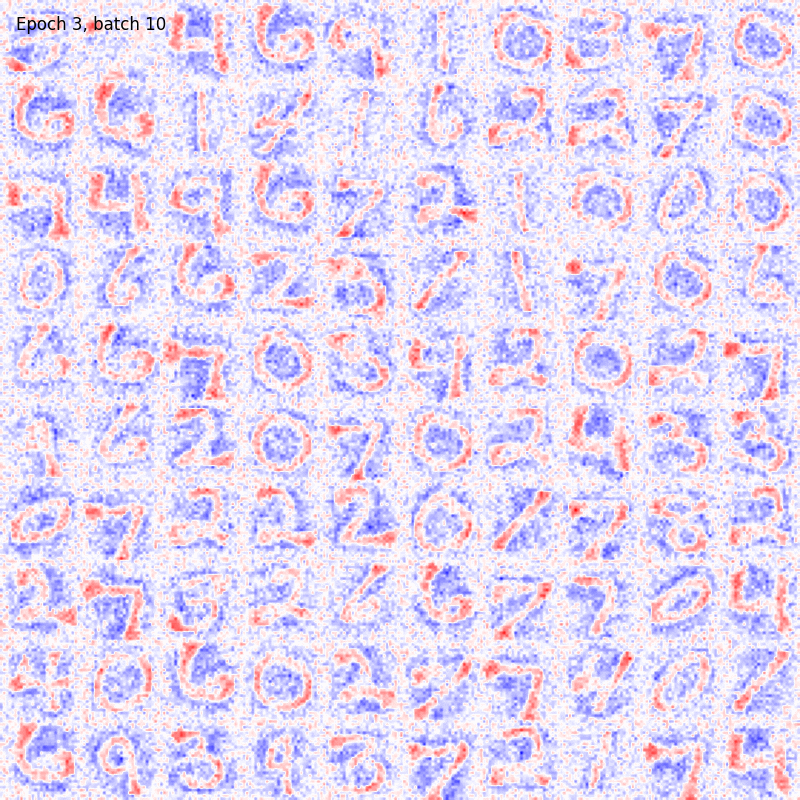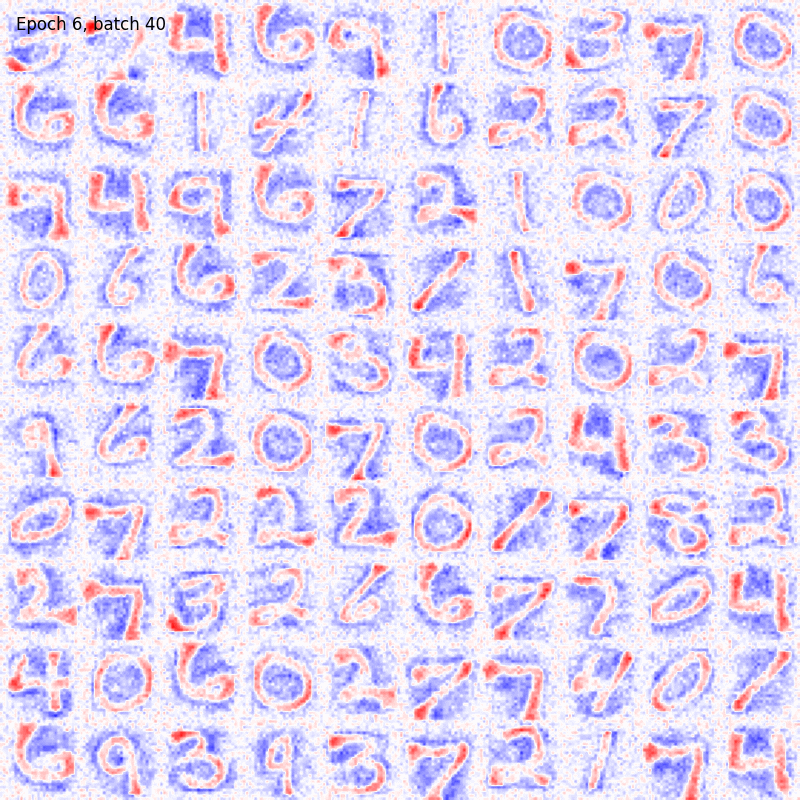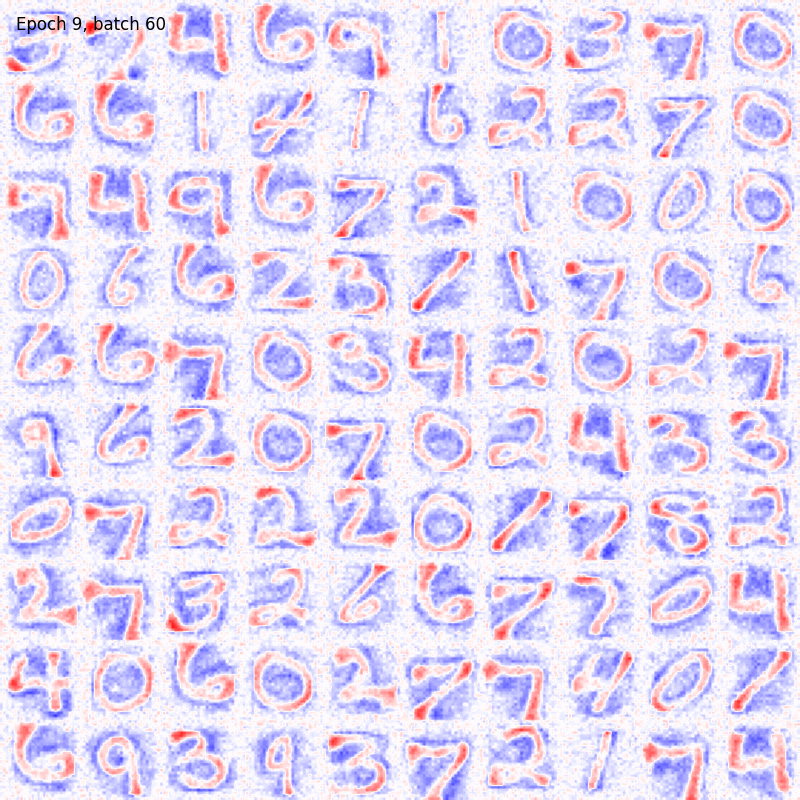
Hopfield model
In the same way of the previous example, first the dataset is imported and then the model is created and fitted: in this case the SGD optimizer (Stochastic Gradient Descent) is used and the neurons outputs don’t need any non-linear activation.
from biolearn.model.hopfield import Hopfield
from biolearn.utils.optimizer import SGD
model = Hopfield(outputs=100, num_epochs=10, batch_size=1000, optimizer=SGD())
model.fit(X)
Again, the receptive fields evolving during training is shown.
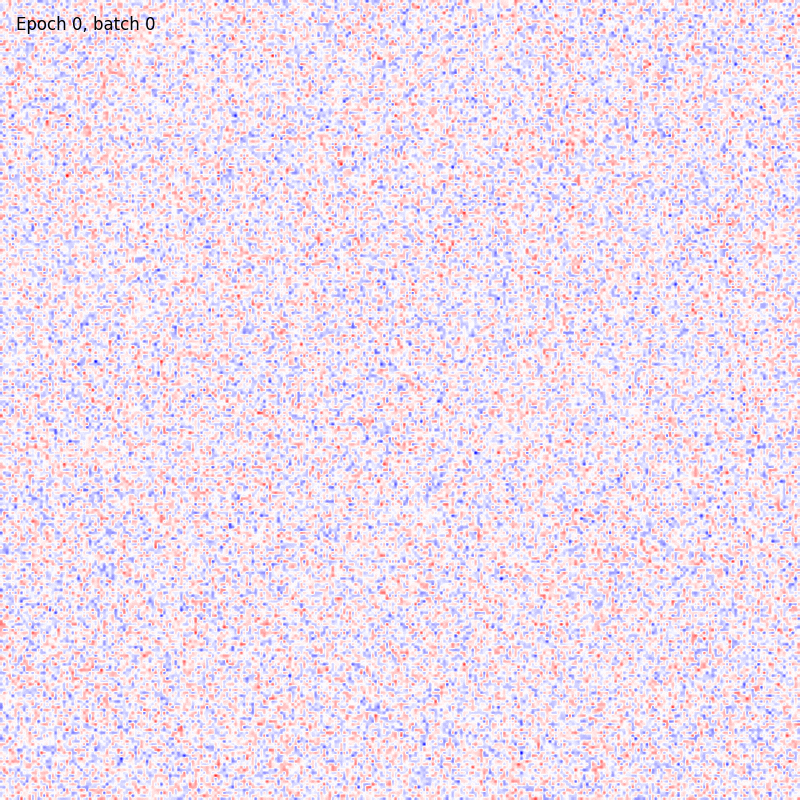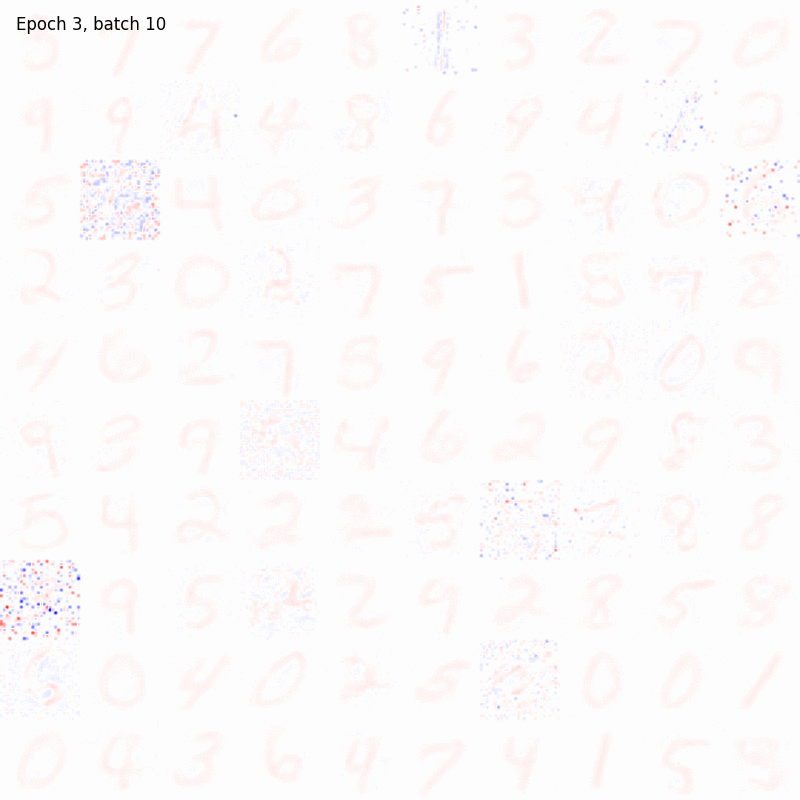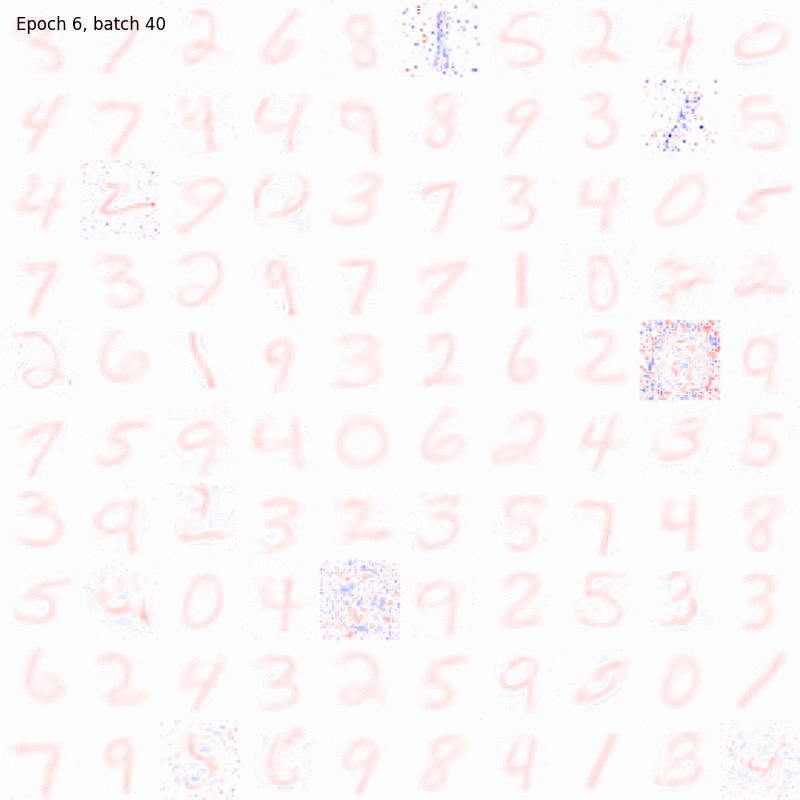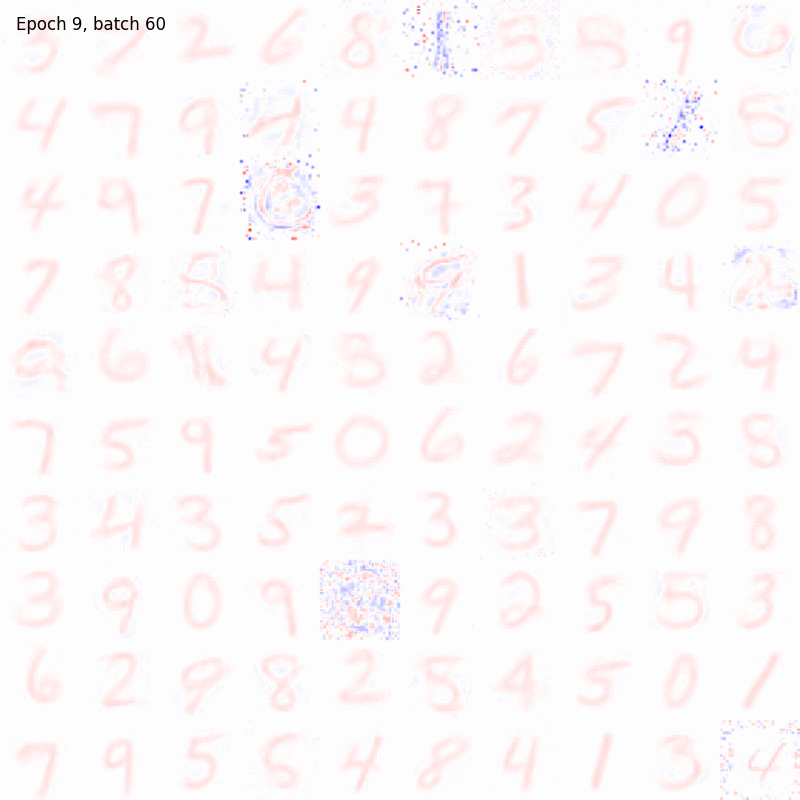
Let’s notice how both the algorithms are able to produce a good encoding of the information about the digits even after few epochs. The BCM model result seem to be noisier but the configuration of its synaptic weights is more stable. In fact, the Hopfield receptive fields are continuously changing over time and, in some cases, they are allowed to randomly flip from one digit to another, preventing the model from reaching convergency. Moreover, all the BCM neurons become sensitive to a specific digit pattern while some of the Hopfield synaptic weights are still random.
However, in the BCM case, the receptive fields of some cells are very similar, meaning that those cells become sensitive to the same pattern (associativity). To force their selectivity, lateral inhibition can be introduced (interaction_strength \(< 0\)), making the training more unstable.
The orthogonalization algorithm applied to weights vectors can represent an alternative approach. In this case, the neurons are forced to become selective to different patterns, first initializing the synaptic weights as orthogonal vectors, and then performing a re-orthogonalization at the end of each training epoch.